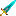Notepad++ didn't help much either. Still only get a Japanese character here and there, in between a hundred other symbols that certainly has got nothing to do with Japanese. :/
Here are a few files. The "junk" data you're seeing is the text pointer table (at top) and other data between lines to tell the game where/how to draw the text. Let me know if these files are "cleaned" enough for your needs.
The game handles each line of text as a separate "sentence" rather than using a standard line-break code between lines. That makes it hard to tell if a text line is part of the sentence above or the beginning of a new sentence.
If I stared at the game's files long enough, I might be able to figure how to make a proper text dumper, but I wasn't planning on taking that much time.
(2012-06-19, 04:22 AM)Guyra link Wrote: Now, how would I go about putting this back into the game after changing it?
Also, if this was easy for you to do(made an app for it, or something?), could you do it with all the files and send me?
To insert changed text, I have been editing the extracted files in a hex editor (ultra edit) then reinserting them into Pack.dat with a second tool I made, then reinserting Pack.dat back into the ISO. But that method means you have to "translate around" all the data junk (pointers etc). If you translate the text-dump files (attached earlier), we'll either have to manually type the new text over the Japanese in a hex editor or take the time to figure out the pointer table format enough to automate the process.
I "cleaned" the text by using a few "search and replace" operations in XVI32 (attached) , which is a a hex editor that supports wild cards. The wildcard feature is a bit confusing, but attached is a picture; mark the "joker char hex" box and type a value into the field to the right, whatever you type will count as the wildcard in the fields above.
"0d0a" is the standard line-break hex value so:
replace "00" with "0d0a" (replaces blank letter slots with line-breaks)
replace "0d0a 0d0a" with "0d0a" several times (removes multiple line breaks next to each other)
replace "0d0a * 0d0a" with "0d0a" (removes some generic data between text lines)
replace "0d0a * * 0d0a" with "0d0a" (removed rest of the generic data between text lines)
The only junk left should be the pointer tables, but they are easy to see/delete in Notepad++.
2014-02-01, 08:19 PM (This post was last modified: 2014-03-28, 04:57 PM by HwitVlf.)
I was working on a menu translation for Hungry Ghosts when I turned this project over to Guyra and it looks like it is dead now. Hunger seems like a really good game from what I saw and was worth translating. It's very artistic and original. If anyone wants to pick up the project and has the know-how, let me know and maybe I can send what was done so far. I was actually converting the games narrative into first person "Will you pick it up?" > "Should I pick it up?" because I thought it deepened immersion and suited the game well. So my work may not be any use for people who want to do a direct translation.
The game already supports English text so you might be able to do a translation without any "hacking" at all - just type the English over the original Japanese text.
Heyo, long time no chat. If you don't mind things taking a while, I'd be interested in helping out with the Hungry Ghosts translation. I was looking for another 'productive distraction' while finishing the thesis.
Mord! Hiya :)
It would be great if you picked up this project. I am so busy right now that I wouldn't be any help. I can tell you that a lot/all of the text is in pak.dat and is in Shift-JIS encoding. There is a lot of text, but I think large passages may be duplications so there is less than it may appear.
Sure, sounds good. I don't foresee being able to sink entire days into this, but I would enjoy doing like 15 minutes a day or so. Slow, but better than never having a finished version!
I looked over this thread again, but I didn't see a link to pack.dat... I guess PM me?
I think it probably makes sense to go about this in a similar way to how I did it before - make a 'true' or strict translation first, then touch things up, make the sentences more natural/coherent and unify the style (e.g., first person like you mentioned earlier) later. And keep everything organized and indexed in a spreadsheet or some other system. Inserting text back into files can happen later; even if it's slightly more work in the long run, it's good to have discrete goals on a big project.
One the organization point: I think I might be able to whip something together to insert the translated text in python without too much headache (ha! watch me eat those words later). Just shooting from the hip here, but I think it would be straightforward enough as I go through the files (automate after getting the hang of it from the first few) to make a note of where the translation-needing text starts and ends, then just save the original text blocks in a python dictionary. Translated versions then can be stored in new dictionaries (making it scalable for translating to other languages, if anyone's interested). Finally, inserting the new text should be relatively easy, since we would have the exact strings to replace (start/stop positions) in the original dictionaries.
Then for keeping track, I could just make a color-coded spreadsheet for progress. (Red=nothing done yet, yellow=needs some work, green=good to go, etc..)
Never worked with hex in python before, but I know it has tools, and it's definitely my language of choice.